当天,腾讯清雅发布新一代混元开源空话语模子。英特尔凭借在东谈主工智能畛域的全栈本事布局,现已在英特尔® 酷睿™ Ultra 平台上完成针对该模子的第零日(Day 0)部署与性能优化。值得一提的是, 依托于OpenVINO™ 构建的 AI 软件平台的可彭胀性,英特尔助力ISV生态伙伴率先收尾愚弄端Day 0 模子适配,大幅加快了新模子的落地进度,彰显了 “硬件 + 模子 + 生态” 协同的广泛爆发力。
混元新模子登场:多维度粉碎,酷睿 Ultra 平台Day 0适配
腾讯混元告示开源四款小尺寸模子,参数辞别为 0.5B、1.8B、4B、7B,浪费级显卡即可出手,适用于条记本电脑、手机、智能座舱、智能家居等低功耗场景。新开源的4 个模子均属于交融推理模子,具备推理速率快、性价比高的特色,用户可字据使用场景生动遴荐模子想考模式——快想考模式提供轻松、高效的输出;而慢想考触及治理复杂问题,具备更全面的推理按次。
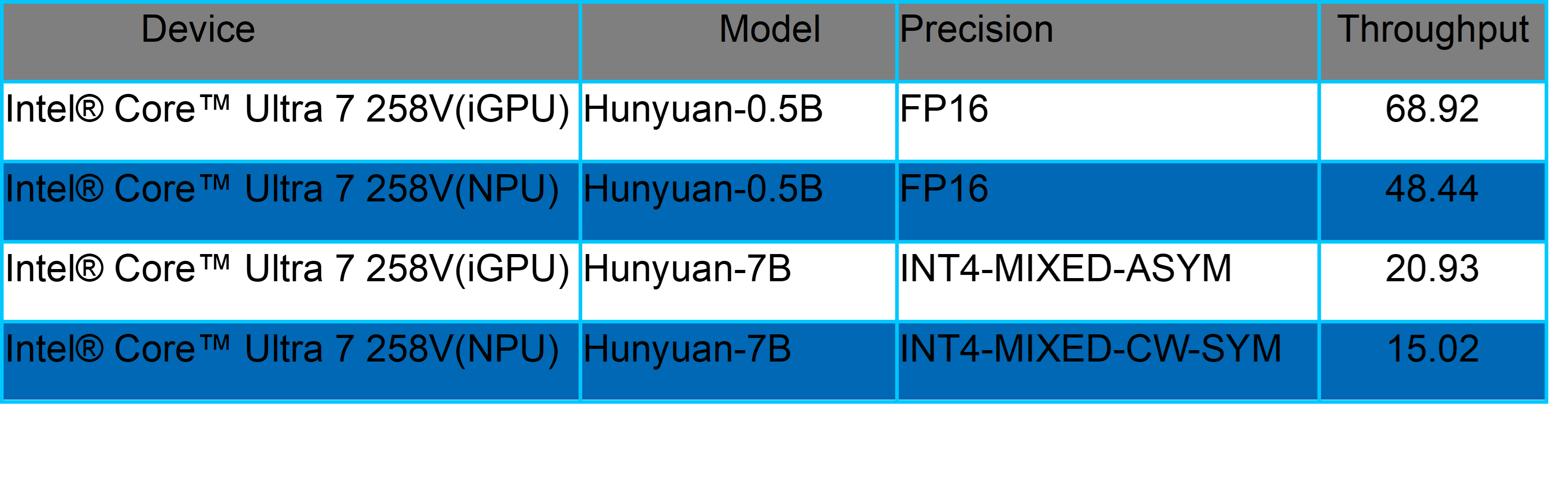
这些模子已在英特尔酷睿 Ultra 平台收尾全面适配,其在 CPU、GPU、NPU 三大 AI 运算引擎上齐展现了超卓的推感性能弘扬1。以酷睿 Ultra 2 代 iGPU 平台为例,7B 参数目模子在 INT4 精度下,糊涂量达 20.93token/s;0.5B 小尺寸模子在 FP16 精度下糊涂量达 68.92token/s。值得一提的是,英特尔对新模子的 NPU 第零日支握已变成常态化能力,为不同参数目模子匹配精确硬件决议,得志从个东谈主结尾到边际斥地的千般化需求。
OpenVINO:新模子快速落地的 “要道引擎”
行为英特尔推出的开源深度学惯用具套件,OpenVINO 以 “性能优化 + 跨平台部署” 为中枢上风,可充分开释英特尔硬件资源后劲,平凡愚弄于 AI PC、边际 AI 等场景。其中枢价值在于能将深度学习模子的推感性能最大化,同期收尾跨 CPU、GPU、NPU 等异构硬件的无缝部署。
当今,OpenVINO已支握逾越 900 个东谈主工智能模子,涵盖生成式 AI 畛域主流模子结构与算子库。这么的模子支握体系,使其能在新模子发布的Day 0,即完成英特尔硬件平台的适配部署。这次混元模子的快速落地,恰是 OpenVINO 本事实力的成功体现 —— 通过其优化能力,混元模子在酷睿 Ultra 平台的性能得到充分开释,为用户带来即发即用的 AI 体验。
生态共创:AI本事到愚弄的 “终末一公里” 加快
生态互助是英特尔 AI 计策的中枢因循,驱动东谈主生行为其永恒互助伙伴,专注于互联网客户端软件研发及运营,本着“以用户为中心,以本事为根柢,以绽放为原则”的理念,永恒勤劳于本事研发和本事革命,为用户提供优质的职业。其 AIGC 助手软件,收尾土产货部署,离线使用,支握笔墨输入、语音转译,将大模子装进背包,可遍地随时与它进行智能对话,还能让它帮衬解读文档,编撰决议。
该愚弄给与 OpenVINO推理框架,借助其快速适配能力,在混元模子发布当日即完成愚弄层适配,成为首批支握新模子的愚弄之一。
当今,驱动东谈主生 AIGC 助手、英特尔AIPC愚弄专区和多家OEM 愚弄商店的 AI PC专区均已上线,搭载混元模子的新版块也将在近期推出,用户可第一时刻体验更智能的交互与职业。这种 “模子发布 - 硬件适配 - 愚弄落地” 的全链条第零日响应,恰是英特尔生态协同能力的生动写真。
AI 的发展离不开模子革命与软硬件生态协同 —— 模子如同燃料,生态则是驱动前进的引擎。英特尔通过硬件平台、软件用具与生态集结的深度协同,收尾对新模子的第零日适配,不仅加快了本事到愚弄的滚动,更鼓吹着通盘 AI 产业的高效革命。翌日,英特尔将握续久了与互助伙伴的协同,让 AI 革命更快走进千行百业与人人生计。
快速上手指南
第一步,环境准备
通过以下号召不错搭建基于Python的模子部署环境。
该示例在以下环境中已得到考证:
硬件环境:
Intel® Core™ Ultra 7 258V
iGPU Driver:32.0.101.6972
NPU Driver:32.0.100.4181
Memory: 32GB
操作系统:
Windows 11 24H2 (26100.4061)
OpenVINO版块:
openvino 2025.2.0
openvino-genai 2025.2.0.0
openvino-tokenizers 2025.2.0.0
Transformers版块:
https://github.com/huggingface/transformers@4970b23cedaf745f963779b4eae68da281e8c6ca
第二步,模子下载和调遣
在部署模子之前,咱们最初需要将原始的PyTorch模子调遣为OpenVINOTM的IR静态图神色,并对其进行压缩,以收尾更轻量化的部署和最好的性能弘扬。通过Optimum提供的号召行用具optimum-cli,咱们不错一键完成模子的神色调遣和权分量化任务:
开发者不错字据模子的输出规则,治愈其中的量化参数,包括:
--model: 为模子在HuggingFace上的model id,这里咱们也提前下载原始模子,并将model id替换为原始模子的土产货旅途,针对国内开发者,保举使用ModelScope魔搭社区行为原始模子的下载渠谈,具体加载形态不错参考ModelScope官方指南:https://www.modelscope.cn/docs/models/download
--weight-format:量化精度,不错遴荐fp32,fp16,int8,int4,int4_sym_g128,int4_asym_g128,int4_sym_g64,int4_asym_g64
--group-size:权重里分享量化参数的通谈数目
--ratio:int4/int8权重比例,默许为1.0,0.6默示60%的权重以int4表,40%以int8默示
--sym:是否开启对称量化
此外咱们无情使用以下参数对出手在NPU上的模子进行量化,以达到性能和精度的均衡。
这里的--backup-precision是指搀杂量化精度中,8bit参数的量化策略。
第三步,模子部署
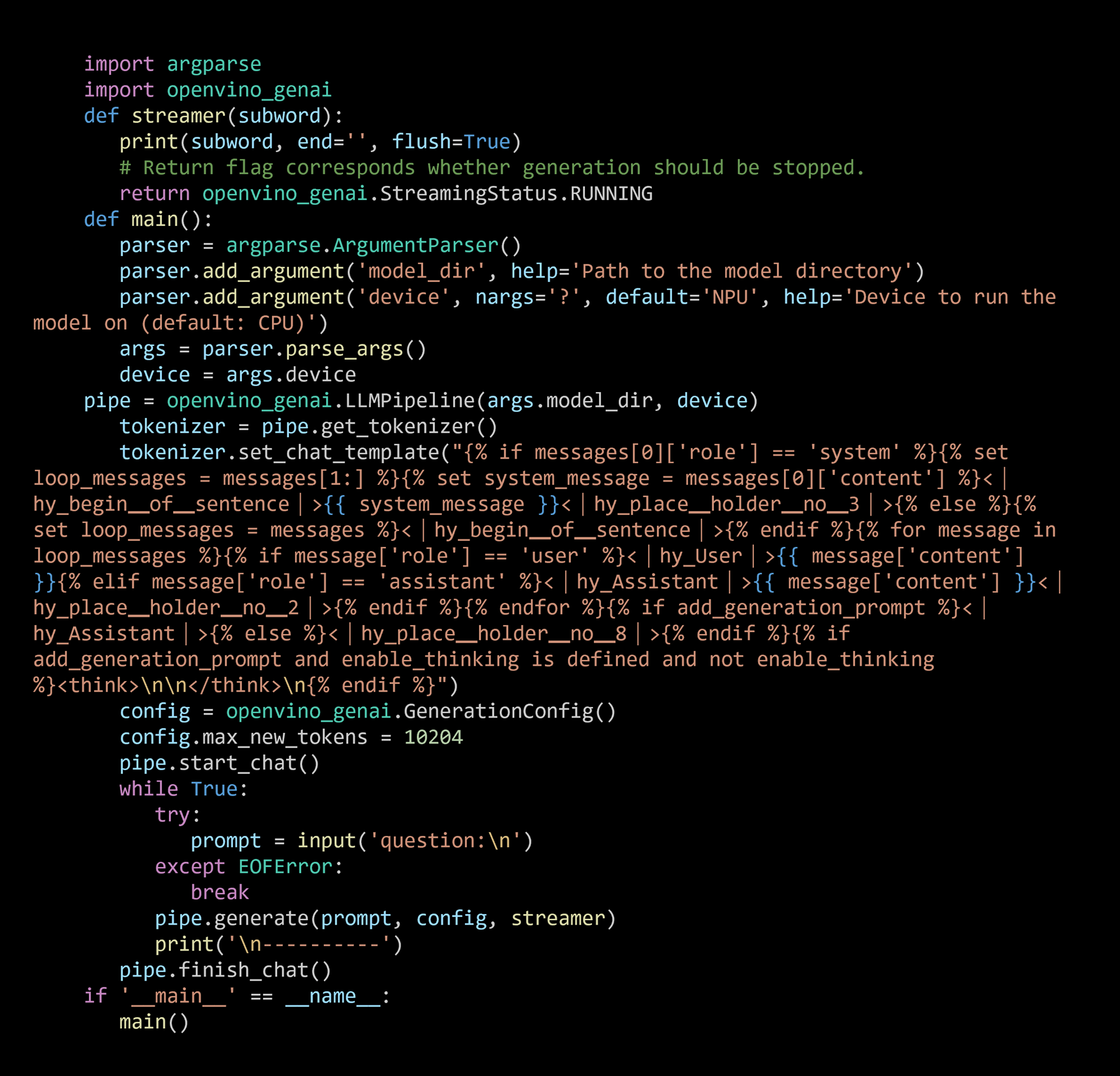
当今咱们保举是用openvino-genai来部署空话语以及生成式AI任务,它同期支握Python和C++两种编程话语,安设容量不到200MB,支握流式输出以及多种采样策略。
GenAI API部署示例
其中,'model_dir'为OpenVINOTM IR神色的模子文献夹旅途,'device'为模子部署斥地,支握CPU,GPU以及NPU。此外,openvino-genai提供了chat模式的构建按次,通过声明pipe.start_chat()以及pipe.finish_chat(),多轮聊天中的历史数据将被以kvcache的形态,在内存中进行管束,从而普及出手后果。
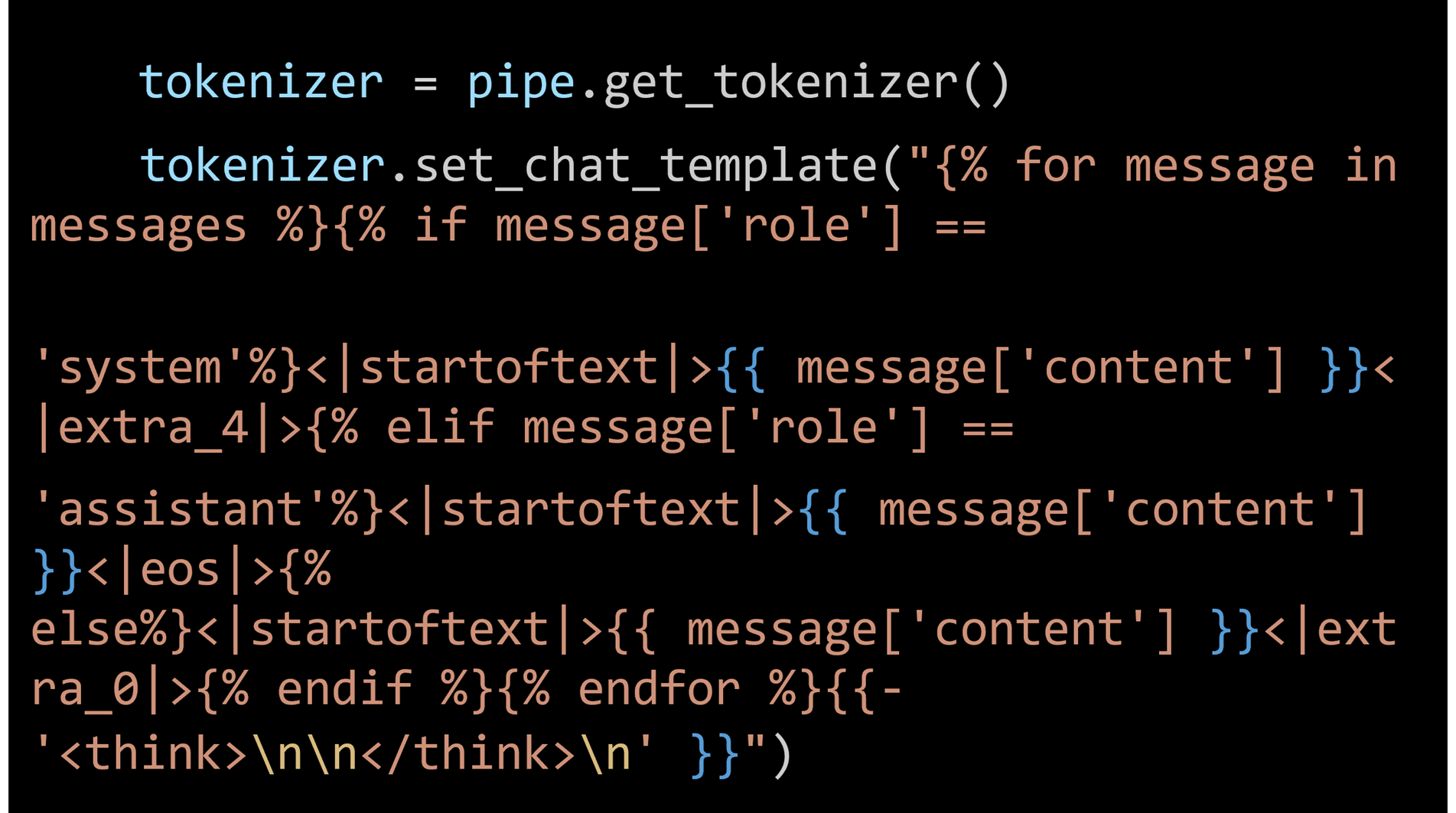
开发者不错通过该该示例的中按次治愈chat template,以关闭和开启thinking模式,具体形态不错参考官方文档(https://huggingface.co/tencent/Hunyuan-4B-Instruct)。由于当今OpenVINOTM Tokenizer还莫得完全支握Hunyuan-7B-Instruct模子默许的chat template神色,因此咱们需要手动替换原始的chat template,对其进行简化,具体按次如下:
chat模式输出规则示例:
对于该示例的后续更新,不错怜惜OpenVINO notebooks仓库:https://github.com/openvinotoolkit/openvino_notebooks/tree/latest/notebooks/llm-chatbot
驱动东谈主生愚弄获取形态:
驱动东谈主生 AIGC 助手(https://www.160.com/aigc/index.html)
英特尔AIPC愚弄专区(intel.cn/aipc)
1.通过使用 OpenVINO 框架版块 2025.2.0 在 英特尔® 酷睿™ Ultra 7 258V 和 英特尔® 酷睿™ Ultra 9 285H 上进行测试获取了性能数据,计较经过发生在 iGPU 或 NPU 上。测试评估了首 Token 的蔓延以及在 int4-mixed、int4-mixed-cw-sym 和 fp16 精度竖立下 1K 输入的平均糊涂量。每项测试在预热阶段后执行三次,并遴荐平均值行为阐明数据。
性能因使用形态、树立和其他要素而异。请走访www.Intel.com/PerformanceIndex了解更多信息。
性能规则基于测试时的树立景况,可能未响应通盘公开可用的更新内容。请参阅关系文档以获取树立细目。莫得任何居品或组件大致保证所有安全。
您的内容老本和规则可能会有所不同。
关系英特尔本事可能需要启用关系硬件、软件或激活职业世博shibo登录入口。